Project Information
- Language: C++
- Graphics API: DirectX 11
- Creation: Y3 S1
- Source URL: GitHub Page
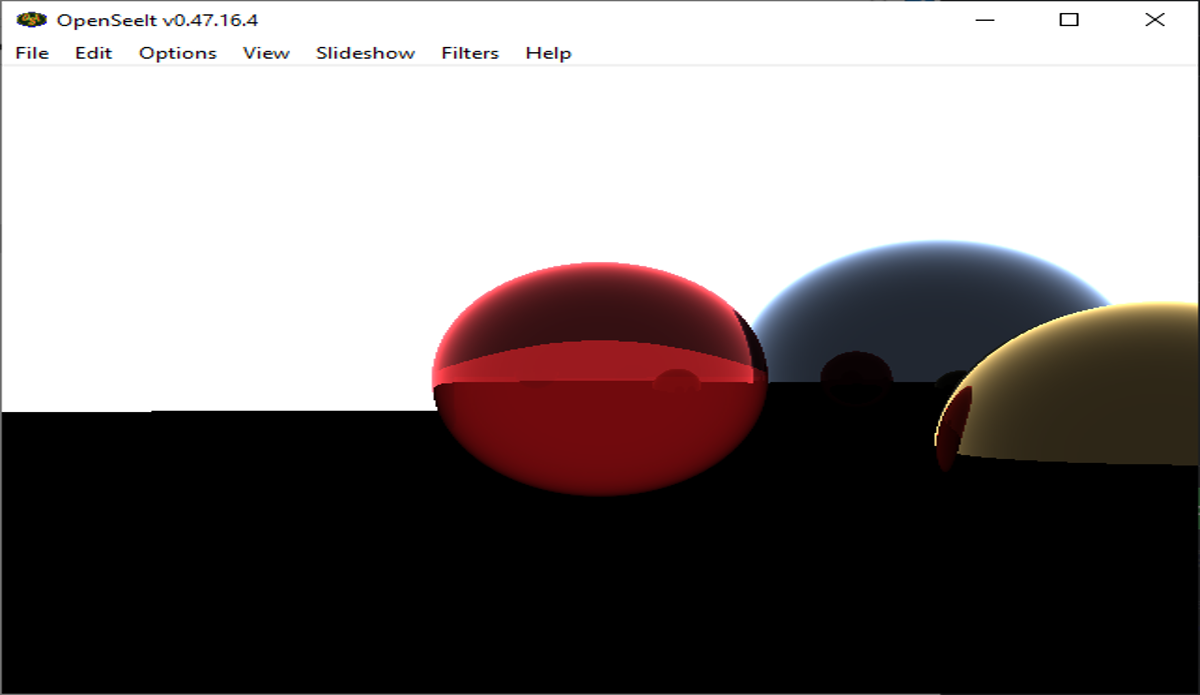
Ray Tracer
Created as part of my Low-Level Programming module in semester 1 of my third year. The task was to modify a ray-tracer algorithm using various memory management and low-level optimization techniques to improve performance by increasing the efficiency of the algorithm. The features implemented include memory pools to defer all memory allocations to the start of the program, multi-threading which was achieved by dividing the number of pixels to be rendered by the amount of threads, having each thread render those pixels and then compile the final image by stitching all the pixels back together. Memory management techniques were implemented to provide a method for retracing the stack and all memory allocations that were made throughout the running of the application.
What Did I Learn?
This project was a great learning experience as it allowed me to learn about the many different memory management techniques that are available to programmers. I also learned about the many different ways in which multi-threading can be implemented and the benefits of each. This project also allowed me to learn about the many different ways in which a ray-tracer can be implemented and the many different features that can be implemented to improve the performance of the algorithm. As one of the additional tasks was to port the project onto Linux, I also learned about the differences between the Windows and Linux operating systems and how to implement the same functionality on both platforms.
A heap manager was implemented which would allocate a heap or a block of data at the start and end of the memory block to be created: the header and footer. Filling the footer with a predetermined value meant that if there were any issues with buffer overflows and the value expected to be found in the footer was something else, this would be a reason to assume that there was an issue with memory allocation.
A memory tracker was also created to keep track of all the heap allocations and deletions that were made throughout the program. It does this using a doubly linked link, connecting the headers and footers of each subsequent heap that is allocated. Iterating through this list at the end of the program and outputting the relevant information; total memory allocated, peak memory allocated, and memory allocation issues such as buffer overflows i.e., walking the heap, provides a good baseline for debugging the program should memory not be allocated as expected.
Using this memory management system, memory pools were implemented. This system pre-allocates blocks of memory for chunk and char data based on the target resolution. These memory blocks are then used by the render system instead of allocating memory for each frame.
.png)
.png)
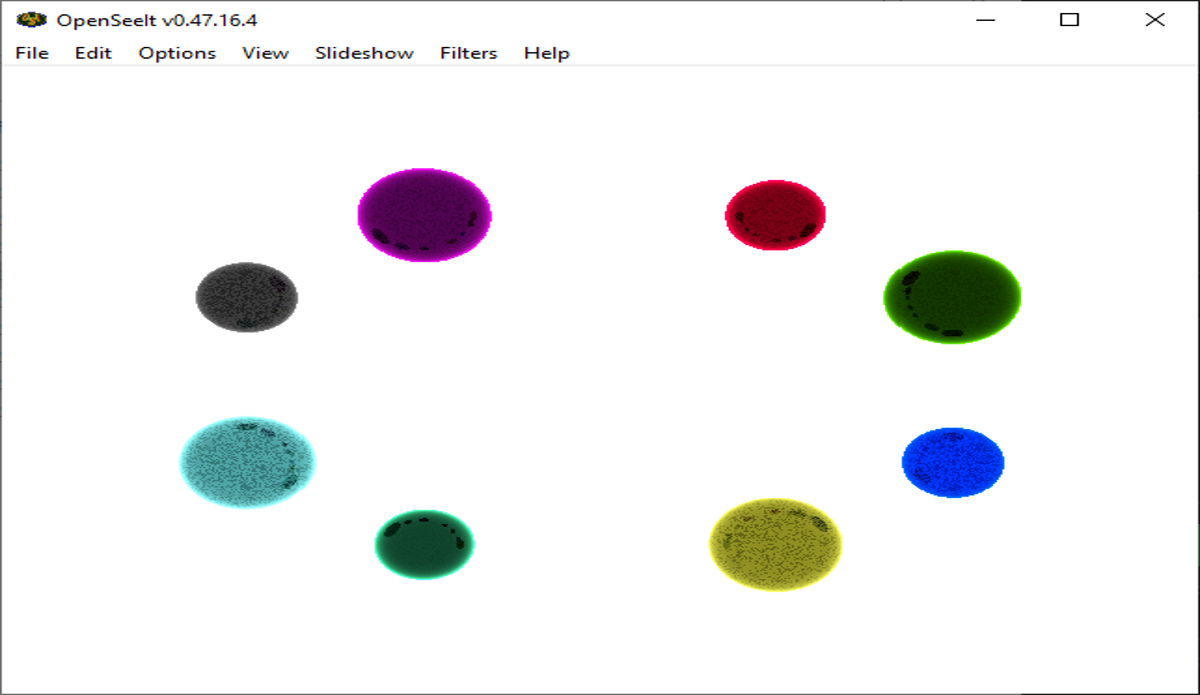
The left image shows, on average, how render times were affected by the memory pool implementation. As memory does not need to be allocated for each render cycle, as it is done ahead of time, this means the actual time it takes to render a single frame is lower, even though the total program execution time remains unchanged. The memory pool system itself does not make the program more efficient, but it does ensure smoother performance as a by-product of offloading memory allocations to the start of the program, ahead of any rendering.
The right image shows that more memory is allocated with the introduction of the memory pool system. Without memory pools, the system will only allocate memory as it is needed, but with memory pools, even though the best guess is made as to how much will be needed, it is still better to ensure in this case that the program has enough memory to access as this would otherwise cause a complete program failure due to possible nullptr references and to account for cache misses.
.png)
.png)
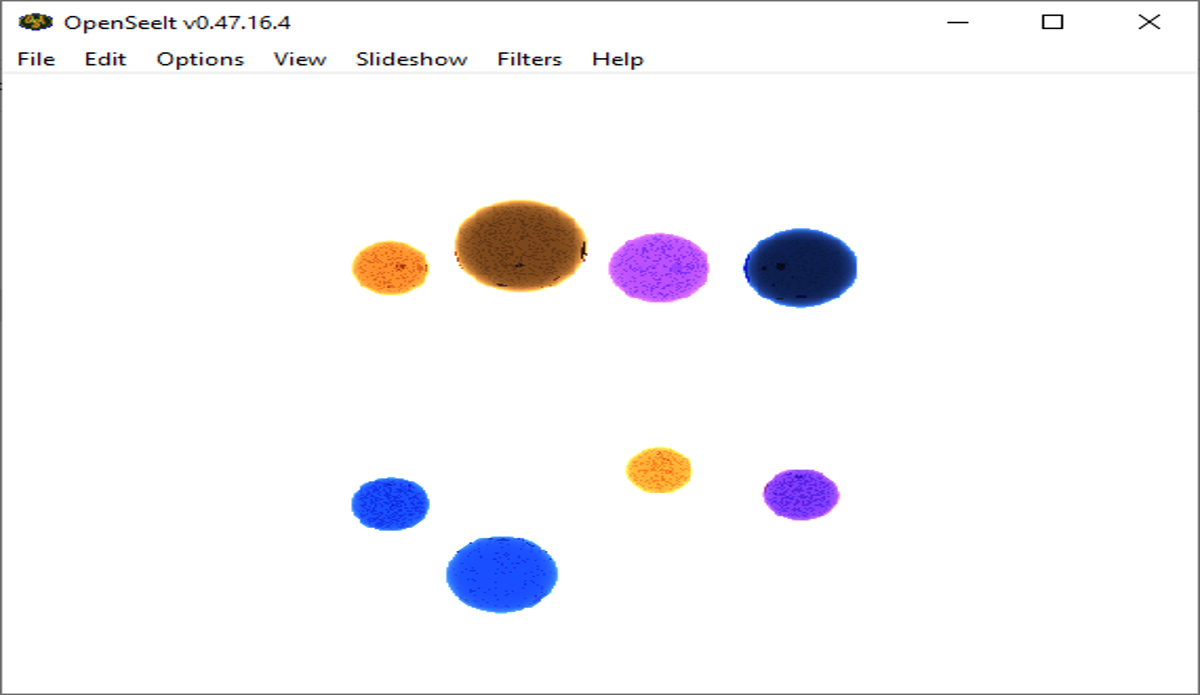
The left image uses the first custom sphere animation as a benchmark to highlight the differences in varying thread counts on the target system. From the graph, a total of four threads is most suited to this system. This was slightly unexpected, as considering the specifications of the target device, the total number of cores available was six, meaning that the total number of logical processors, or threads, available was twelve. The reason for this is that the device was using those resources for other purposes at the time the results were gathered. This, however, does not explain why even though four threads saw an increase in performance, why the increase was so minimal.
To understand this, research was done to understand when too many threads start to hurt performance. The issue of false sharing occurs when threads on different processors share cache lines inadvertently which ultimately impairs the efficient use of the cache, (Weisner, C., R., 2022). From this, it can be determined that when more threads are being used than there are logical processors available, the system will naturally rely on available threads from different cores to ensure efficient multi-threaded performance.
Thus, the issue is that too many threads were created, and with the overhead that a single thread requires, this eventually caused diminishing returns on the target device with an ever-increasing thread count. Therefore, it is understood that when gathering results, the test environment was not entirely ideal since more threads would have had to be in use, such as for other programs running, for a total of eight threads to start to see these diminishing returns.
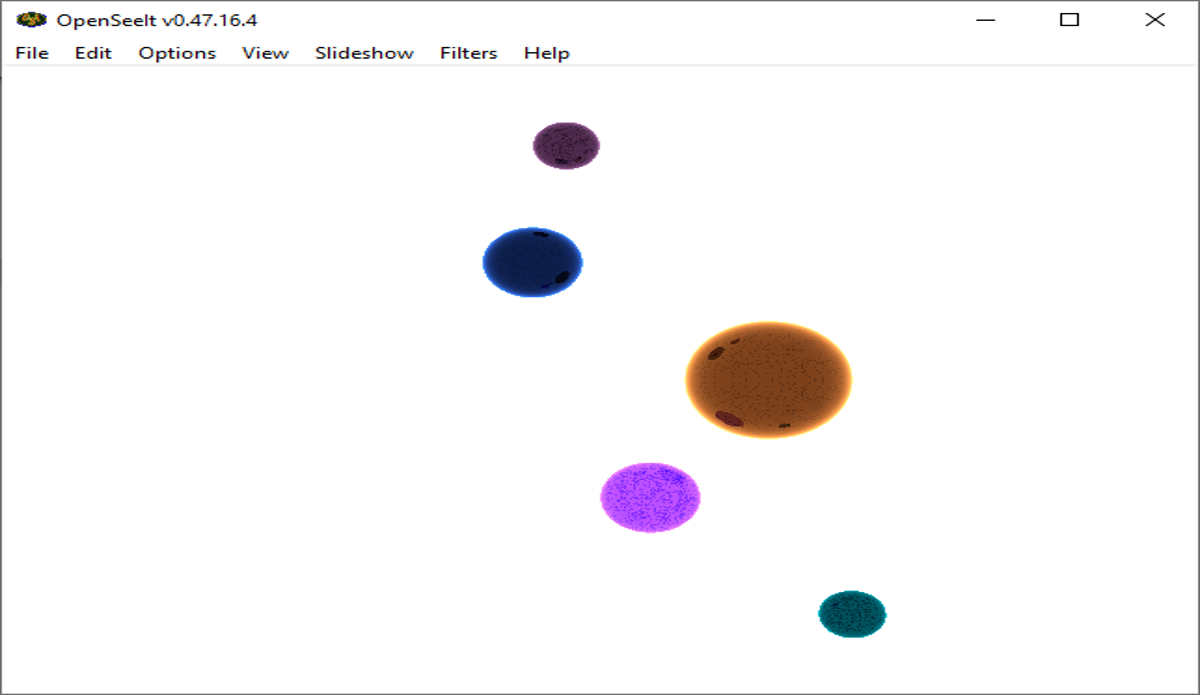
After removing the parallel for loop, the efficiency of the multi-threading system improved quite substantially, as shown in right image. This is due to the overhead that the parallel for requires, and that it is more focused on being used separately in a multi-threaded system since the parallel for loop itself incorporates parallelism for each loop body iteration. Thus, a definition was created to ignore this code in the completed version of the program, except when parsing data from a JSON file, as the parallel for loop ensures that sphere animation is always rendered accurately.
.png)
The above image compares the time taken to render the smooth scale sphere animation at a lower resolution for both the original and completed frameworks, and on both target platforms, Windows, and Linux. The program execution times are ideal concerning the original task: improving the performance of the ray tracer algorithm. However, in this case, when comparing program execution times using a benchmark, Linux offers some strange results.
It is expected that the optimized version of the program running on Linux would not be as fast as it would be on Windows, however, this does not explain the faster execution times on the base ray tracer algorithm. Research showed that for both the g++ and GCC compilers: g++ being the one that was used to compile on Linux, they are always more advantageous in performance (Jun, M., 2019), especially over the built-in compilers in Visual Studio. Certain sources reported that the built-in Visual Studio compilers were anywhere between 1.5-2.0x slower at program execution. This explains the discrepancy between the execution times of the original ray tracer algorithms. It is also understandable why the Linux version did not benefit as much from the multi-processing because as previously discussed, resource limitations were introduced with the virtual machine.
Future Additions
Further optimizations to be made to improve performance and execution times would be to incorporate quad or oct-trees to further partition the scene into elements that could be computed concurrently. Object subdivision would be another example of this which would further improve the efficiency and thus performance of the ray tracer algorithm.